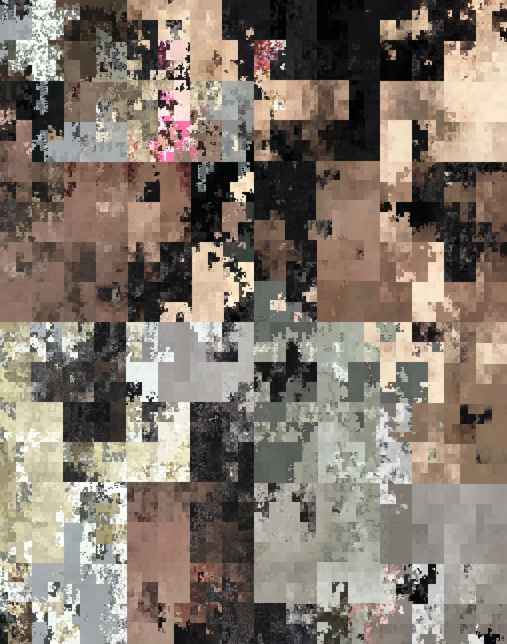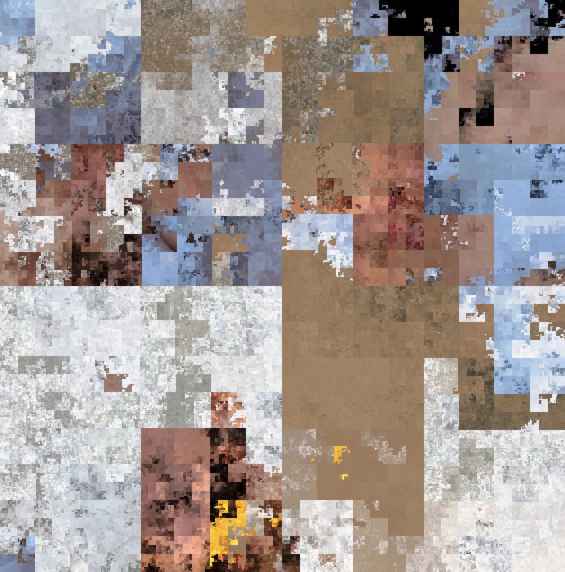详细解读小番茄图片混淆的原理和算法与实践

很多人第一次用小番茄图片混淆,会有两个直觉:第一,混淆后怎么会乱成这样;第二,它为什么又能完整还原。这个问题看着像“黑科技”,其实核心逻辑并不神秘:同一套像素重排规则,正着走是混淆,反着走就是还原。
这篇文章不绕弯子,我们直接按“代码怎么做 + 数学为什么成立 + 实际使用要注意什么”三条线讲清楚。
如果你更关心工具入口本身,可以先看这篇 图片解混淆在线的工具有哪些?;如果你对部署名词有疑问,也可以顺带看 小番茄图片混淆工具netilfy是啥?。
一、先说结论:它不是“涂抹”,是“搬家”
小番茄混淆不是给图片加马赛克,也不是做模糊处理。它做的事只有一件:
- 取出每一个像素
- 按规则把它搬到新位置
所以像素值本身(RGBA)没有被改写,只是坐标改变了。你可以把它理解成把一本书的页码全部重新排序:内容还在,但阅读顺序被打乱了。
这也是它可逆的根本原因。
二、代码主流程:processImage 到底做了什么
在 index-tool.ts 里,核心处理流程可以概括成四步:
- 读取图片宽高
width、height - 生成二维遍历路径
curve = gilbert2d(width, height) - 计算偏移量
offset - 把原像素按“旧位置 -> 新位置”重排
对应关键公式是:
offset = round(((√5 - 1) / 2) × width × height)
记总像素数 N = width × height,路径上的第 i 个点记作 curve[i],那么混淆时本质是:
newIndex = (i + offset) mod N
也就是把路径上的像素做一个循环位移。因为是 mod N 的环状映射,所以不会越界,也不会丢像素。
三、为什么用 gilbert2d 路径,而不是一行一行扫
如果你按普通“从左到右、从上到下”去重排,虽然也能打乱,但容易产生条纹和规律。小番茄使用的是 gilbert2d 生成的二维空间填充路径,它会尽量保持“局部连续”。
通俗说:这条路径像蛇形钻满整张图,把二维平面映射成一维序列。这样重排后,图像块之间被打散得更自然,不容易看出明显人工痕迹。
generate2d(...) 的递归逻辑本质是在做“分块 + 方向控制”:
- 当区域很细时直接线性填充
- 否则切成更小的块继续递归
- 通过向量方向
(ax, ay)、(bx, by)控制遍历方向
这部分数学上属于空间填充曲线思想,工程上则是“高质量的遍历顺序生成器”。
四、解混淆为什么一定能还原
很多人关心“会不会有误差”。理论上,只要输入图片没被改过,按同参数解混淆就能回去。
理由很简单:混淆映射是一个双射(1 对 1)。
混淆:P(i) -> P((i + offset) mod N)
解混淆就是逆映射:
P(i) <- P((i + offset) mod N)
在代码里对应两行差异:
enc:从旧位置取像素,放到新位置dec:从新位置取像素,放回旧位置
这就是“同一把钥匙正转上锁,反转开锁”。
五、为什么平台压缩后会解不开
这是用户最常遇到的坑。你以为“看起来一样”,但算法要的是“像素和尺寸完全一致”。
一旦图片经过微信、QQ、微博等平台二次处理,常见变化有:
- 宽高变化(例如 1170×2532 变成 1080×2336)
- 像素值变化(JPEG 重压缩)
- 元数据和颜色空间被改写
而我们的路径和偏移都依赖 width × height。只要 N 变了,路径序号就全变,逆映射自然失败。这不是工具失效,而是输入条件已经不是原始混淆图。
六、工程上的两个细节:性能和稳定性
1)大图先缩放
代码里有安全阈值:最大约 800 万像素、单边 4000。超限会先等比缩放再处理,避免浏览器内存暴涨和页面卡死。
2)双 requestAnimationFrame
在点击混淆/解混淆后,会先让 UI 有机会渲染“处理中”状态,再进入重计算,用户体感更流畅,不会误以为按钮没反应。
七、给普通用户的实用建议
如果你只关心“怎么用不翻车”,记住这 4 句就够:
- 解混淆只对“混淆图”有效,原图别点解混淆。
- 混淆后尽量保存原文件,不要走社交平台中转。
- 别裁剪、别加字、别旋转,再小的改动都可能破坏还原。
- 大图处理慢是正常现象,属于本地计算成本,不是上传卡顿。
八、总结
小番茄图片混淆的核心并不复杂:用 gilbert2d 生成稳定路径,再做基于黄金比例偏移的循环重排。数学上是可逆映射,工程上是前端本地像素运算。
它的价值不在“绝对安全加密”,而在“低门槛、可逆、隐私友好”的视觉保护。对聊天截图、临时分享图、社交互动图这类场景,它非常实用;对高安全等级保密场景,则建议叠加密码学加密方案。